From Lab to Community: Research Where It Matters Most
December, 2024
The Project
For the past few months, I’ve had the opportunity to work as a visiting research intern at The Institute for a Disaster Resilient Texas (IDRT), affiliated with The Texas A&M University. My project was about improving object geolocation for post-disaster management. Basically, I worked with computer vision algorithms and math formulas to make sure building coordinates are as accurate as possible—something that’s super important when every second counts during disaster recovery and management.
Why I Joined
The motivation behind this project was pretty simple: I wanted to quench my thirst for research that directly impacts society. Previously, I worked on biomedical research aimed at developing a deployable product for breast cancer detection. It’s an incredible and important field, with groundbreaking work happening in places like the Mahmood Lab. But it’s also a popular area, with abundant resources and brilliant minds already driving innovation. This time, I wanted to step into a less crowded, often overlooked space—something deeply connected to the community, where computer scientists are needed but resources are scarce. That’s how I found my way to IDRT. The project checked all the boxes: impactful, community-focused, and aligned with my skills. So, I reached out, and soon enough, I was on board as a research intern for the semester. It felt like the perfect way to bridge research and real-world community needs. I truly believe research exists to benefit humanity. But let’s face it—many great ideas don’t make it past a published paper or a GitHub repo. They often lose their community-driven purpose somewhere along the way. This project was different. By working within an institute like IDRT and leveraging a community-driven database, I felt like I was taking my first step—not just as a researcher, but as someone genuinely contributing to the community. It was my way of giving back and making sure that the work we do in research finds its way back to the people who need it most.
How it's going
I oversaw most of the technical aspects of this project. The technical workflow can be divided into three major components:
Data Collection → Building Detection → Image Retrieval
I focused on fine-tuning the object detection model for identifying damaged buildings and applying image similarity models for efficient image retrieval. As demonstrated in [1], vision models can be effectively used as similarity metrics. Trained vision models can serve either as loss functions for training new networks requiring specific perceptual similarity or as standalone similarity metrics. In our research, we utilized vision models as off-the-shelf similarity metrics to embed the original images and conduct image retrieval based on the embedded representations. We used the post-disaster building dataset, referred to as the NOAA database, as the query dataset, and Google Street View images with accurate geolocation information as the target dataset.
Results and Experiments
Results so far indicate high performance in building detection. For fine-tuning, I used the dataset presented in [2]. Figure [1] illustrates the performance comparison, highlighting improvements in average precision and detection rates after fine-tuning. Figure [2] shows the detection rates for the query and target datasets.
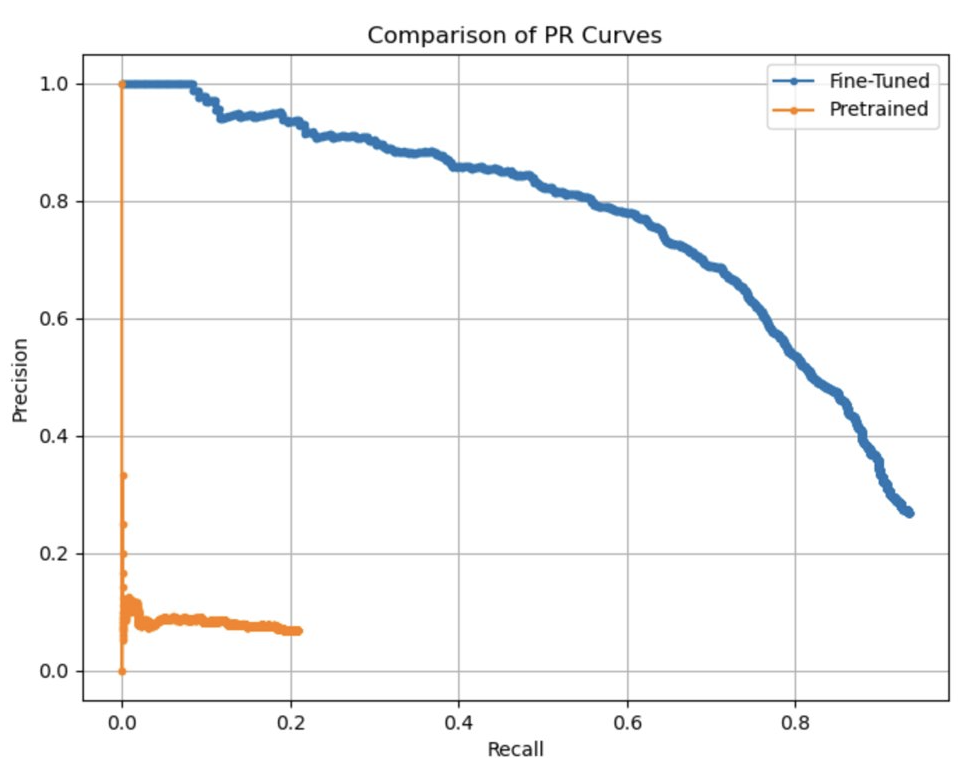
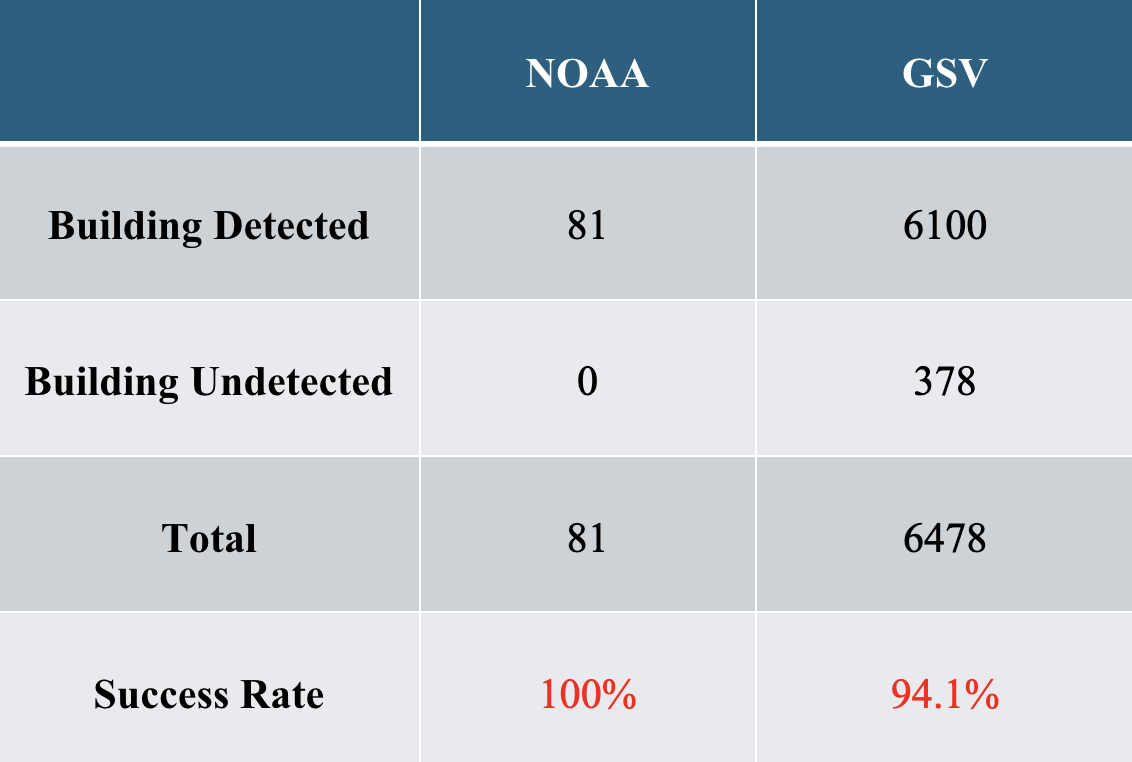
Regarding image retrieval, we are experimenting with four different models. Among them, I am currently testing DINO [3] and DreamSim [4]. The final results will be presented in our upcoming paper.
Here is a quick preview of our retrieval results from DreamSim. Figure 3 presents: (a) and (b) as top-1 retrieval cases, while (c) and (d) illustrate failed retrieval cases (ranked below the top 5). Our attention maps highlight the weight distribution of attentions based on [5]. Although Figure 3 showcases only four examples, we achieved a 62% top-1 retrieval accuracy and a 93% top-5 retrieval accuracy using off-the-shelf similarity models for our full dataset. Unlike conventional Siamese Neural Networks, which require extensive fine-tuning, we demonstrate that perceptual similarity models can be effectively applied to post-disaster scenarios for disaster management.

References
[1] Sundaram, Shobhita, et al. "When Does Perceptual Alignment Benefit Vision Representations?." arXiv preprint arXiv:2410.10817 (2024).
[2] Zhao, Kun, et al. "Bounding boxes are all we need: street view image classification via context encoding of detected buildings." IEEE Transactions on Geoscience and Remote Sensing 60 (2021): 1-17.
[3] Caron, Mathilde, et al. "Emerging properties in self-supervised vision transformers." Proceedings of the IEEE/CVF international conference on computer vision. 2021.
[4] Fu, Stephanie, et al. "Dreamsim: Learning new dimensions of human visual similarity using synthetic data." arXiv preprint arXiv:2306.09344 (2023).
[5] Hila Chefer, Shir Gur, and Lior Wolf.Transformer interpretability beyond attention visualization.In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 782–791, 2021.